中 알리바바 연구진, AI 시스템 'EMO' 선봬
사진만으로 이야기하고 노래하는 영상 제작

인물의 사진 한 장과 오디오 클립만 있으면 그 사람이 말하거나 노래하는 영상을 매우 실감나게 만들어낼 수 있게 됐다. 물론 인공지능(AI) 덕분이다. 28일(현지시간) IT 전문매체 벤처비트(VentureBeat)는 중국 알리바바(Alibaba)의 지능형 컴퓨팅 연구소 연구진이 새로운 AI 시스템 'EMO(Emote Portrait Alive)'를 개발했다고 보도했다. 해당 연구 논문은 논문 사전 공개 사이트인 아카이브(arXiv)에 게재됐다.
EMO는 영상에 들어갈 오디오에 어울리는 자연스럽고 표현력이 풍부한 얼굴의 움직임과 머리 포즈를 구현할 수 있다고 한다. 기존 기술로는 종종 사람 표정·표현의 전체적인 스펙트럼이나 개개인 얼굴 스타일의 특징을 포착하기 어려웠다는 게 연구진의 설명이다. 이 같은 문제 해결을 위해 알리바바 연구진은 오디오와 비디오를 직접 합성하는 접근법을 선택했다.
EMO 시스템은 사실적인 합성 이미지 생성에 효과적인 확산 모델(Diffusion Model)을 사용한다. 연구진은 연설을 비롯해 영화와 TV 쇼, 노래 공연 등에서 선별해 250시간 이상의 말하는 얼굴 비디오 데이터 세트를 기반으로 모델을 훈련시켰다. EMO는 이전 방법들과는 달리 오디오 파형을 비디오 프레임으로 직접 변환한다. 이로써 미묘한 움직임과 개별적인 특징·버릇을 포착할 수 있어 자연스럽게 발화하는 모습이 가능해졌다.
연구 논문에 따르면 EMO는 영상의 품질은 물론 인물의 정체성 보존과 표현력 등을 측정하는 지표에서 기존 방법들보다 훨씬 우수한 성능을 보인 것으로 나타났다. EMO로 생성된 영상이 다른 시스템에 의해 만들어진 영상보다 더 자연스럽다는 평가다. 또 EMO는 말하는 영상 외에도 사진 속 인물이 적절한 입 모양과 얼굴 표정으로 노래하는 영상도 만들어낼 수 있다. 아울러 입력된 오디오의 길이에 맞춰 영상을 생성하는 게 가능하다.
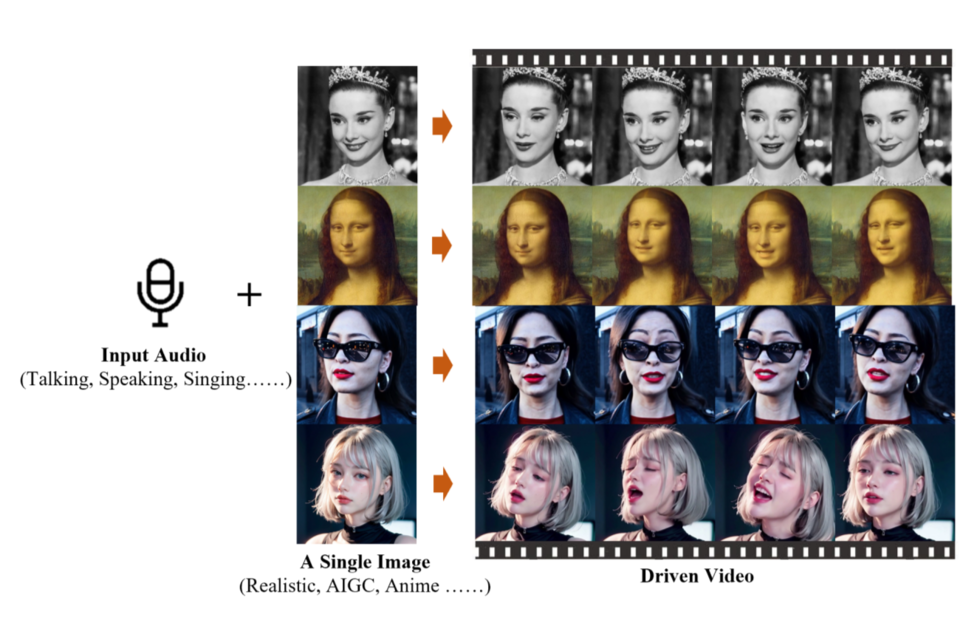
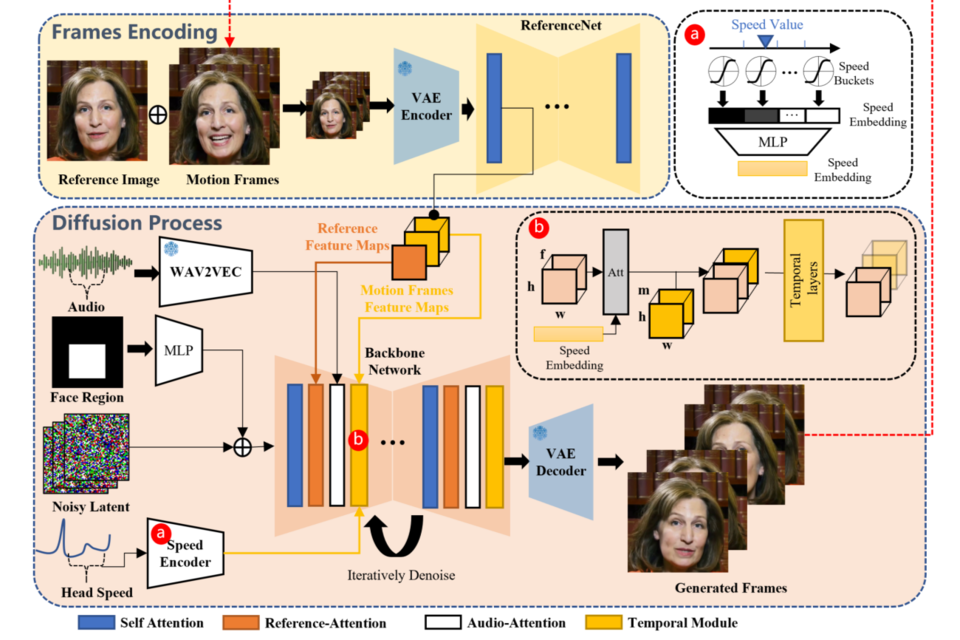
이번 연구 성과로 향후 사진과 오디오 클립만 있으면 개인화된 영상 콘텐츠를 손쉽게 제작할 수 있는 길이 열린 셈이다. 반면 이러한 기술이 오용될 경우 야기될 윤리적 문제에 대한 우려도 존재한다. 이에 알리바바 연구진은 합성 비디오를 감지하는 방법을 연구할 계획이라고 밝혔다.
AI포스트(AIPOST) 윤영주 기자 aipostkorea@naver.com