
요즘 검색을 하다 보면 가끔씩 '이 콘텐츠가 정말 사람이 만든 것인지, 혹은 인공지능(AI)이 생성한 콘텐츠인지' 궁금할 때가 많아진다. 딱 보더라도 이건 AI가 자동생성한 거구나라는 것을 알아챌 수 있을 정도로 티 나는 콘텐츠도 많이 있다. 그러나 최근에는 수준이 높아져, 쉽게 눈치를 채기 어려워지고 있다.
생성 AI 모델은 이미 인터넷에 공개된 콘텐츠를 크롤링해서 만들어지고 있다. 또 이러한 모델에서 새롭게 만들어진 콘텐츠는 '물론 누구나 특별한 조건 없이 조회할 수 있도록 공개된 콘텐츠'를 통해 만들어졌다. 분명 콘텐츠 생산자는 이 과정에서 AI가 활용하는 것에는 동의하지 않은 경우도 많을 것. 텍스트뿐만 아니라 이미지, 영상 등 콘텐츠 유형이 점차 다양해진다.
이에 대한 이용 권한 역시 콘텐츠 생산자 입장에서 충분히 제어할 수 있길 원하지만, 현재의 웹 크롤러는 이런 세분화된 권리 표현을 할 수 있는 표준화된 방법이 없다. 게다가 RAG(Retrieval-Augmented Generation)와 같은 AI 기술들을 이용해 모델이 아닌 서비스로서 인터넷에 공개된 콘텐츠를 가져가서 활용하는 경우도 늘어나고 있다.
이러한 방식으로 콘텐츠가 이용되는 것에 대해 콘텐츠 생산자가 동의를 했는가 역시 사회적 합의가 제대로 이뤄졌다고 볼 수 없다. 완전히 불가능한 것은 아니다. 현재 기존 'Robots.txt' 프로토콜을 그대로 활용해서 'Yes or No'를 할 수 있는 수준으로 볼 수 있다. 예를 들어 오픈AI GPTBot은 ‘User-agent: GPTBot'을 통해 차단 여부를 정할 수 있도록 가이드하고 있다.
최근 구글이 개최한 '2023 Google I/O(Input Output)'에서 향후 AI 콘텐츠의 사용성을 고려한 프로토콜 업데이트 협의(AI Web Publisher Controls)를 시작했다. 전 세계 기술, 콘텐츠 퍼블리셔 등 업계 관계자들이 함께 참여해 주길 요청했다. 이를 리딩하고 있는 팀은 구글 검색 관계 관리(Google Search Relations Team)팀이고, 이 팀은 구글 SEO에 대한 가이드 문서를 제공하고, 구글 봇 표준을 관리하는 업무를 하는 팀이다.
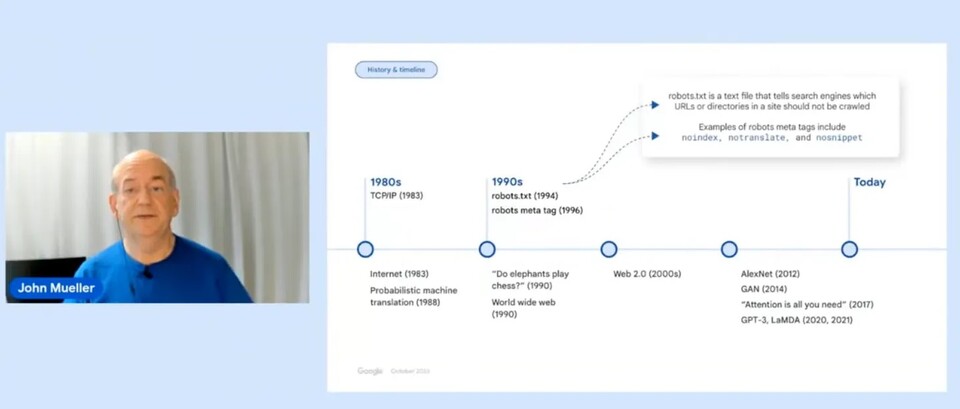
이 협의를 통해 새로 업데이트되는 Robots.txt Protocol은 Google Bard, Vertax AI에 적용될 계획이라고 한다. 이렇게 되면 사실상의 웹 표준으로 받아들여질 가능성이 높으니 이 논의가 향후 AI 콘텐츠의 공개적인 사용에 대한 표준이 될 수 있을 정도로 매우 중요한 논의라고 생각된다. 이와 관련 구글 서치팀이 최근 게시한 'AI 웹 퍼블리셔 컨트롤 킥오프' 영상에 주요 담론들이 담겼다.
정리해 보자면 이렇다. 첫 번째 의제는 Alignment이다. 크롤링 봇이 과거 주로 검색 등 웹을 다루는 곳이 중심이었다면 이제는 AI 업계로 확장된다. 구글 역시 이러한 확장을 고려해서 새롭게 AI 목적에 맞도록 포괄적으로 컨트롤할 수 있는 프로토콜로서 Robots.txt가 기능하기 위해 새로운 옵션, 택소노미(taxonomy) 등 웹, AI 업계, 콘텐츠 생산자 모두 일관성 있는 기준이 필요하다.
특히 웹 콘텐츠 생산자는 40억 개 이상의 호스트가 존재하는데, 이러한 40억 개 호스트가 최대한 영향을 받지 않도록 하는 표준을 만드는 것이 매우 중요하다고 보고 있다. 두 번째 의제는 Transparrency이다. 봇이 콘텐츠 호스트에 접근할 때, 봇이 왜 접근하는지 목적을 명확하고 투명하게 제공할 수 있어야 한다. 호스트는 봇의 목적을 보고 콘텐츠 접근 여부를 정할 수 있으므로 봇이 충분한 정보를 제대로 제공하는 것이 중요하다.
이러한 표준을 잘 지키기 위해 구글 검색 봇은 충분히 정보를 제공하고 있고, 다른 봇들도 그러하길 기대하고 있는 눈치로 보인다. 이를 위해 봇 정보를 중앙에서 등록하고 호스트가 접근가능한 레지스트리 도입도 하나의 대안으로 언급된다. 세 번째 의제는 Granularity이다. 검색엔진과 생성AI 앱 등에서 사용되는 목적, 방식 등이 완전히 다를 수 있기 때문에 이를 나누는 과정. 또 AI 안에서도 목적 세분화가 잘 이루어져야 한다.

이용 방식에 따른 허용 등 생산자가 잘 정의된 경우가 아니라면 분명 AI 발전이 오히려 닫힌 인터넷으로 가도록 만들 수도 있다. 그렇다고 너무 세분화되면 부작용도 많을 것이다. 새로운 목적, 사용방식을 가진 크롤러가 계속 등장할 것을 고려해서 이러한 새로운 유형이 계속 늘어나도 호스트 영향도는 최소화 돼야 합니다. 네 번째 의제는 'Adoption'이다. 구글 등의 검색, 웹 업계뿐 아니라 관련된 AI 업계 및 스타트업 그리고 웹 콘텐츠 생산자까지 관계자가 정말 많다.
그러면서도 최대한 다수가 이를 존중하고 적용할 수 있어야 비로소 제대로 된 표준으로서 기능할 것이기 때문이다. 이를 위해 여러 가지 도구를 만들어야 할 수도 있다. 봇에서 사용되는 Certificate 인증 탑재도 고려될 수 있다. 첫 번째 피드백 일정이 11월 28일 마무리됐다. 조만간 이와 관련된 내용을 구글에서 공유할 것이라고 본다.
킥-오프 논의 내용 관련 정보나 뉴스 기사, 영상 조회수 등을 보면 이슈화가 잘 되지 않고 있다. 하지만 분명 Robots.txt는 당장 검색 사업자인 구글 입장에서는 너무 중요한 표준이다. 네이버, 구글 모두 Robots.txt 표준에 선언된 사이트 게시자의 의도를 보고 해당 웹사이트의 콘텐츠를 무단으로 가져가지 않고 있다. 그렇기에 인터넷에서 검색사업자가 현재 웹 콘텐츠를 제공하는 것 역시 콘텐츠 생산자와의 합의하에 검색서비스를 제공하고 있다고 말할 수 있다는 것.
그래서 이번 Robots.txt의 개선방향은 웹뿐만 아니라 향후 AI 업계 사업자들에게 일종의 콘텐츠 사용권을 인정받는 것으로 볼 수 있게 되는 중요한 과정이라고 생각된다. 이러한 협의에 국내 AI 업계도 적극적으로 참여하고 의견을 내면 좋겠다는 마음을 갖고 있다. 스닙팟도 웹 콘텐츠 크롤러 봇을 운영하고 있는 정보 제공 사업자이기 때문에 Robots.txt를 준수하고 있다. 이번 프로토콜 개선이 어떻게 진행될지, 관심이 크다.
주요 학력
▲ 고려대학교 물리학 학사
▲ KAIST 웹사이언스 공학 석사
주요 경력
▲ SK C&C IT컨설턴트
▲ 스닙팟 창업 & 대표
이성규 스닙팟 대표는?
고려대학교 졸업 후 SK C&C 에서 IT컨설턴트로 근무하던 중 2012년에 정보검색 및 인공지능 연구를 보다 심화시키기 위해 한국과학기술원(KAIST) 정보검색&자연어처리 연구실에서 석사과정으로 입학하였다. 이 때 추천시스템 및 LDA (Topic Modeling) 에 대한 연구에 집중하였다.
이후 연구 주제인 Topic Modeling 을 활용 주제별로 정보를 공유하는 서비스를 만들기 위해 스타트업 스닙팟 (Snippod) 을 창업하였다. 이후 주제를 기반으로 웹 콘텐츠를 모아서 보여주는 서비스를 개발하는 한편 인공지능 기반 추천시스템 기술을 NTIS(국가과학기술지식정보서비스)에 적용하였다.
현재는 #해시태그 기반으로 열린 정보 공유 플랫폼 스닙팟 iOS/Android 앱을 런칭하고 발전시키는 데에 집중하고 있다.
AI포스트(AIPOST) 이성규 스닙팟 대표 shalomeir@gmail.com