
네이버가 이미지 분석과 해석에 탁월한 거대언어모델(LLM) '하이버클로바X 비전(HyperCLOVA X Vision)' 모델을 공개했다. 각종 벤치마크 결과 일부 성능은 오픈AI의 GPT-4V를 넘어서는 것으로 나타났다.
네이버는 최근 자사 블로그를 통해 이미지와 텍스트를 이해하는 멀티모달 기능을 탑재한 '하이버클로바X 비전' 기능을 공개했다. 비전 기능을 개발하는 과정에서 고품질의 원천 데이터를 확보해 활용했다는 점이 경쟁사와의 차별점이다.
이번에 공개된 하이퍼클로바X 비전은 문서의 이해를 포함한 여러 가지 능력을 갖추고 있다. 네이버는 국내에서 가장 앞선 텍스트 관련 능력은 물론 안전 관련 요소들도 놓치지 않도록 다방면으로 노력을 기울였다고 설명했다. 이는 최근 논란이 되고 있는 저작권 침해, AI 안전 등 문제를 염두에 두고 개발에 임했다는 의미다.

네이버가 공개한 하이퍼클로바X 비전은 문서, 이미지 내 글자를 이해하고 상황을 추론할 수 있다. 특히 별도의 객체 인식 모델을 사용하지 않음에도 불구하고 이미지의 세세한 부분까지도 정확하게 인식하고 묘사한다. 또 이미지만 보고도 상황에 대해 추론하거나 다음 단계를 예측할 수 있다.
한글 문서뿐만 아니라 한자, 영어, 일본어로 작성된 문서도 이해할 수 있다. 유머나 문화를 이해할 수 있는 매우 고차원적인 수준의 능력을 갖춘 것도 특징이다. 이미지와 텍스트 쌍으로 구성된 다량의 데이터를 학습했기 때문에 밈에 대한 이해도 가능하다.
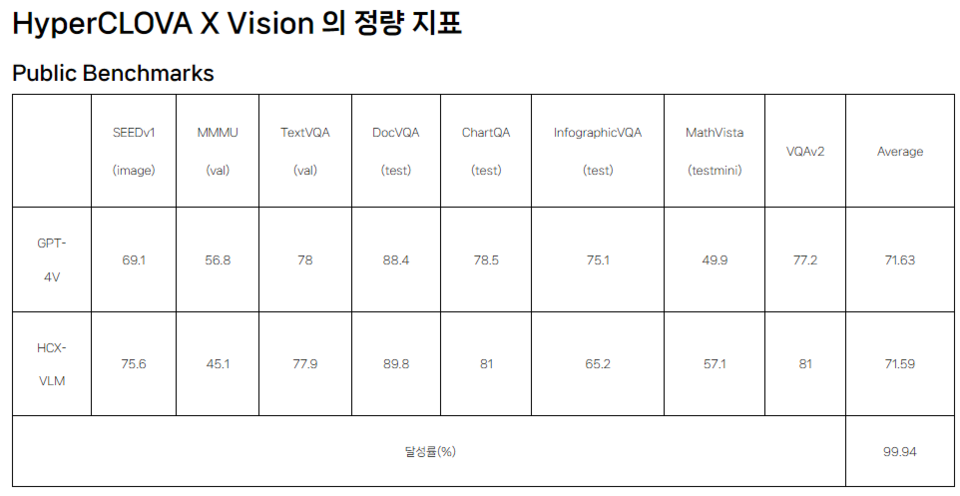
이미지를 보고 코드를 생성할 수도 있고, 도형이 포함된 수학 문제를 이해하고 풀이를 제공할 수도 있다. 네이버는 하이퍼클로바X 비전의 성능이 오픈AI의 GPT-4V에 버금간다고 설명했다. 하이퍼클로바X 비전의 MMMU 등 8개 지표 평균 점수는 71.59점으로 GPT-4V(71.63) 대비 0.04점 낮다. 일부 성능은 GPT-4V를 넘어섰다는 설명이다.

특히 하이퍼클로바X 비전에 대한민국 초 · 중 · 고등학교 검정고시 문제를 이미지 형태로 제공했더니 83.8%의 정답률을 보였다고 한다. 검정고시의 합격 기준점은 60%이며 77.8%인 GPT-4o보다 높은 성능을 보인 것이다.
네이버 측은 "현재 하나의 이미지에 대한 이해에서 나아가 수백만 단위의 컨텍스트 길이를 활용하여, 한 시간 이상 분량의 영화를 통째로 이해한다거나, 스트림으로 연속적으로 들어오는 영상을 이해하는 것이 가까운 시일 내에 가능해질 전망이다"라고 밝혔다.
AI포스트(AIPOST) 조형주 기자 aipostkorea@naver.com