
샌프란시스코에 본사를 둔 인공지능(AI) 스타트업 라이터(Writer)는 최근 새로운 인공지능 모델을 선보이며 대규모 투자 유치에 고삐를 바짝 죄고 있다. 투자자들은 라이터가 경쟁사와 달리 비용효율적인 AI 학습 방법을 구축했다는 점에 주목하고 있다.
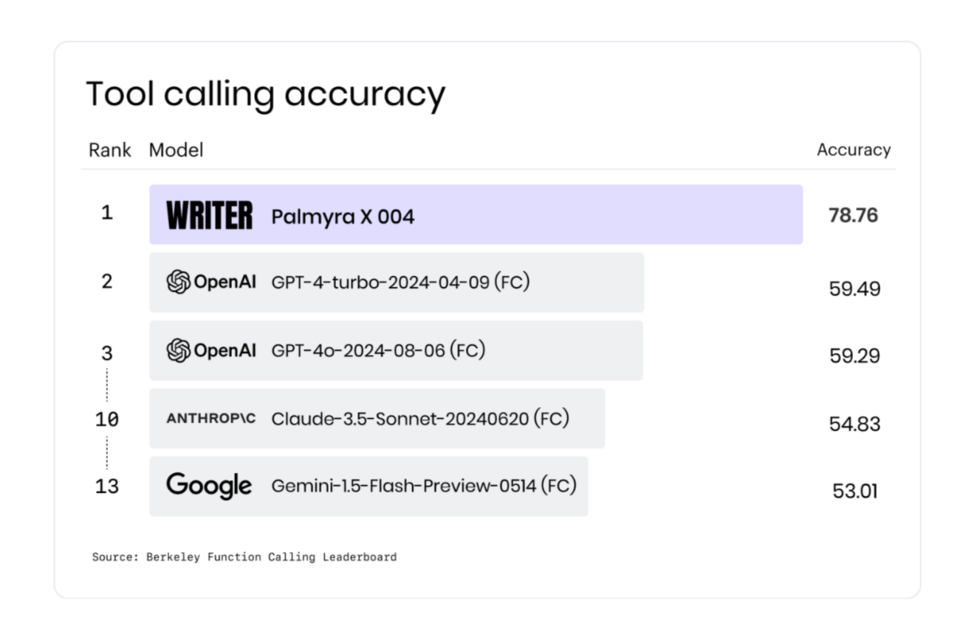
기업을 위한 풀스택 생성형 AI 플랫폼을 개발한 라이터는 최근 거대언어모델(LLM)인 '팔미라 X 004(Palmyra-X-004)'를 출시했다. 새로운 모델은 벤치마크에서 경쟁사를 능가했다고 라이터 측은 밝혔다. 팔미라 X 004는 개발자가 고유한 비즈니스 시스템과 통합된 복잡한 AI 앱을 보다 쉽게 구축할 수 있도록 지원한다.
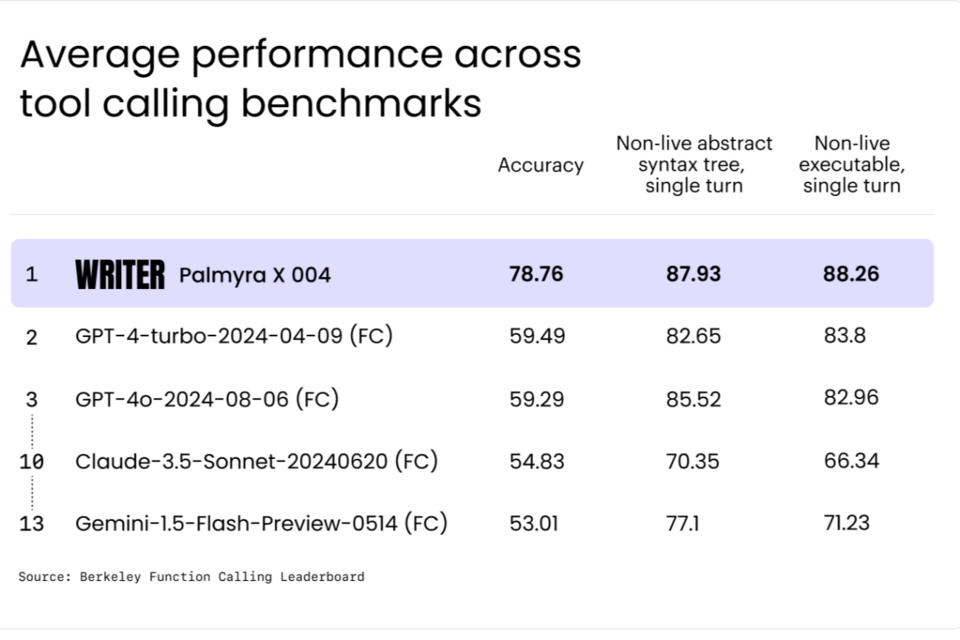
해당 모델은 코딩을 간소화하고 의사 결정을 자동화할 수 있다. 도구 호출을 통해 자연어에 대한 응답으로 다양하고 강력한 다중 작업 워크플로를 활성화하는 것이 더 쉬워진다는 설명이다. 금융 기관은 API를 통해 외부 금융 데이터베이스에서 자동으로 데이터를 가져오고, 기능에 따라 정의된 복잡한 분석을 수행하고, 대시보드를 업데이트할 수 있다.
제조업 분야의 비전문가도 코드를 작성하지 않고 제품 및 공급망 데이터를 검색하고 SQL 쿼리를 실행할 수 있다. 의료 기관에서는 규정을 준수하고 개인 정보를 보호하면서 환자 건강 기록에서 관련 환자 데이터를 자동으로 가져와 청구 처리를 자동화할 수 있다.
그러나 이처럼 특정 분야에 특화된 AI 모델은 이미 시중에 다수 출시돼 있다. 투자자들은 AI 모델을 비롯 라이터만의 특유의 학습 방식에 주목하고 있다. 최신 모델을 훈련하는 데 보통 수백만 달러 규모의 자금이 쓰이고 있는 가운데 라이터는 약 70만 달러(약 9억 5000만원)밖에 쓰지 않았다.
비결은 합성 데이터다. AI가 만든 데이터를 활용해 모델을 훈련시켰기 때문에 비용을 절감할 수 있었다고 한다. 일각에선 합성 데이터가 모델 성능을 저하시키고, 기존 편향을 심화시킬 수 있다고 지적한다. 이에 라이터의 공동 창립자인 와심 알시크는 "수년간 합성 데이터 파이프라인을 개발해 왔다"라고 밝혔다.
환각 데이터로 모델을 훈련시키지 않고, 무작위 데이터를 생성하기 위해 모델을 사용하지 않는다고 한다. 라이터는 실제 데이터를 기반으로 더 명확하고 깔끔한 방식으로 구성된 합성 데이터를 만든다고 전했다. 자체적인 합성 데이터 파이프라인을 통해 믿을 수 있는 AI 모델을 구현한다는 뜻이다.

이처럼 훈련에 투입되는 비용을 획기적으로 줄인 점이 투자자들에게 관심을 받고 있다. 라이터는 기업가치 19억 달러(약 2조 5697억원)를 목표로 투자금 유치 고삐를 죄고 있다.
메이 하비브 라이터 CEO는 "라이터는 LLM 발전의 새로운 시대를 개척하고 있다"라며 "큰 데이터 셋은 한계에 도달하고 있다. 라이터의 접근 방식이 중요한 기업 요구 사항을 충족하는 동시에 시장을 앞지르는 성과를 낼 것으로 기대한다"라고 밝혔다.
AI포스트(AIPOST) 조형주 기자 aipostkorea@naver.com