
미국 실리콘밸리 팔로알토에 본사를 둔 인공지능(AI) 스타트업 패스티노(Fastino)가 고성능 그래픽처리장치(GPU) 없이도 AI 모델을 학습시킬 수 있는 AI 모델 아키텍처를 개발했다.
패스티노는 애쉬 루이스 최고경영자(CEO)와 조지 헌-멀로니 최고운영책임자(COO)가 지난해 9월 설립한 AI 스타트업이다. 오픈AI가 투자한 기업으로도 잘 알려져 있다.
패스티노는 7일(현지시간) 코슬라 벤처스가 주도한 시드 투자 라운드에서 1750만 달러(약 245억원) 규모의 투자금을 유치했다. 이로써 패스티노는 설립 8개월 만에 2500만 달러(약 350억원)을 끌어모았다.
패스티노는 이번에 유치한 자금을 통해 AI 모델 개발에 박차를 가하고, 뛰어난 연구진을 확보할 것이라고 밝혔다. 패스티노의 사명은 모든 개발자가 어디에서나 강력하고 가벼운 AI 모델을 사용할 수 있도록 하는 기술을 개발하는 것이다.
이를 목표로 삼은 패스티노는 단 몇 개월 만에 저가형 게이밍 GPU로 AI 모델을 학습시킬 수 있는 작업 특화 언어 모델(TLMs·Task specific Language Models)을 개발했다. 구체적인 사용자 수나 성능은 아직까지 공개되지 않았다.
그러나 패스티노의 TLMs를 사용한 초기 사용자들의 반응이 뜨겁다고 한다. 애쉬 루이스 CEO는 "TLM은 작업별 벤치마크에서 GPT-4o보다 15% 이상 우수한 성능을 보인다"라며 "이 모델은 개발자와 에이전트를 위한 것이다"라고 밝혔다.
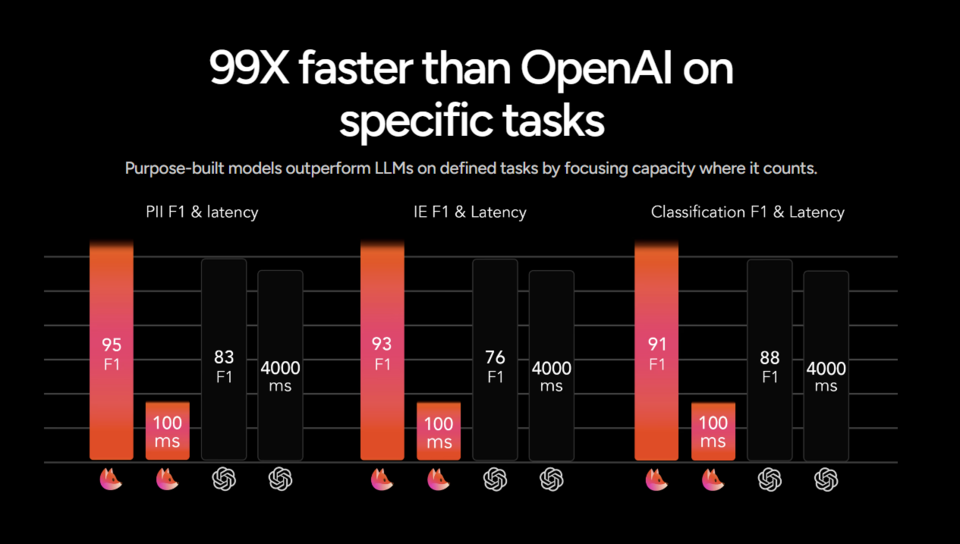
그는 "범용 LLM은 이제 더욱 정밀한 LLM으로 대체되고 있다"라면서 "첫 투자자가 오픈AI라는 점은 이러한 변화를 뒷받침하고 있다"라고 덧붙였다. 패스티노가 제시한 TLMs는 훈련 비용을 크게 줄이면서도 특정 작업에서 뛰어난 성능을 제공한다는 설명이다.
특히 텍스트 데이터 구조화, 검색 증강 생성(RAG), 텍스트 요약, 정보 추출 등 기업들이 주로 수행하는 작업에 최적화됐다고 한다. 패스티노의 모델은 10만 달러 미만의 엔비디아 게이밍 GPU로 학습됐고, 이 과정에서 H100 모델을 전혀 사용하지 않았다는 후문이다.
패스티노 측은 "토큰당 수수료가 폭등하는 현상에서 벗어나고자 한다. 개발자를 위한 최초의 월 구독 모델을 제공한다"라며 "예상치 못한 청구서 걱정 없이 모든 TLM API를 사용할 수 있다. 사용자당 매달 최대 1만건의 요청을 처리할 수 있다"라고 했다.

투자를 주도한 코슬라 벤처스의 파트너인 존 추는 "프런티어 모델을 사용하는 대기업들은 일반적으로 제한된 작업 집합의 성능에만 관심이 있다"라며 패스티노의 기술을 사용하면 기업은 관심 있는 작업에 대해서만 프런티어 모델보다 뛰어난 성능을 가진 모델을 만들 수 있다"라고 했다.
한편 MS도 최근 소형중앙처리장치(CPU) 환경에서 구동할 수 있는 인공지능(AI) 모델 '비트넷(BitNet)'을 공개한 바 있다. 더불어 인도 AI 기업인 지로랩스(Ziroh Labs)는 인도 공과대학교 마드라스 캠퍼스와 함께 개발한 AI 플랫폼 '컴팩트 AI(Kompact AI)'를 출시했다.
AI포스트(AIPOST) 유형동 수석기자 aipostkorea@naver.com