구글 딥마인드, AI 모델의 정확성 평가하는 벤치마크 공개

구글 딥마인드가 거대언어모델(LLM)이 장문의 문서를 작성할 때 얼마나 정확한 정보를 내놓는지를 평가하는 새로운 벤치마크를 선보였다. 이 벤치마크를 활용해 여러 인공지능(AI) 모델을 평가한 결과 구글의 '제미나이(Gemini)' 제품군이 가장 정확한 답변을 제공하는 것으로 나타났다.
구글 딥마인드는 최근 온라인 데이터 분석 플랫폼인 '캐글(Kaggle)'을 통해 새로운 벤치마크인 '팩츠 그라운딩(FACTS Grounding)'을 공개했다. 이 벤치마크는 AI 모델이 사용자가 요청한 프롬프트에 얼마나 유용하고 관련성 있는 답변을 제공하는지, 응답이 상세한지에 대해 평가한다.
연구진은 LLM 사전 훈련이 이전 토큰을 기준으로 다음 토큰을 예측하는 데 중점을 두기 때문에 응답의 정확성을 보장하는 것이 어렵다고 설명했다. AI 모델의 사전 훈련은 매번 사실적인 답변을 하기 보다는 그럴듯한 텍스트를 생성하도록 장려된다.
이를 해결하기 위해 구글 딥마인드는 LLM이 LLM을 평가하는 방식을 선택했다. 긴 형식의 응답이 필요한 860개의 공개 샘플과 859개의 비공개 샘플을 통합해 연구에 활용했다. 예를 들어 모델에 "회사 수익이 3분기에 감소한 주요 이유를 요약해달라"라고 요청한 뒤 답변의 정확성을 평가하는 식이다.
만약 AI 모델이 "회사는 3분기에 수익에 영향을 미치는 문제에 직면했다"라는 수준의 답변을 내놓으면 부정확한 답변으로 간주한다. 자세하고 정확한 답변을 했을 때 정답으로 평가했다는 것이다. 다양한 입력을 허용하기 위해 연구자들은 3만 2000개의 토큰(2만 단어)에 달하는 다양한 길이의 문서를 벤치마크에 포함시켰다.
금융, 기술, 의학, 법률 등 다양한 분야가 포함됐다. 사용자 요청이 광범위하기 때문에 Q&A 생성, 요약, 재작성 등 요청도 평가하도록 연구진은 설계했다. AI 모델에 대한 평가는 제미나이 1.5 프로, GPT-4o, 클로드 3.5 소네트 등이 수행했다.
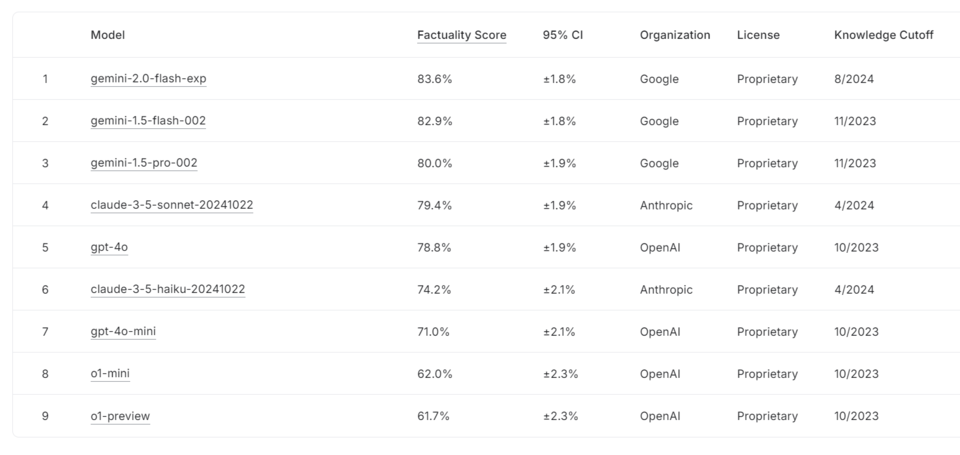
이를 근거로 각종 AI 모델을 평가한 결과 구글의 제미나이 2.0 플래시가 정확도 83.5%로 1위를 차지했다. 2위는 제미나이 1.5 플래시, 3위는 제미나이 1.5 프로, 4위는 클로드 3.5 소네트, 5위는 GPT-4o, 6위는 클로드 3.5 하이쿠, 7위는 GPT-4o 미니, 8위는 o1-미니, 9위는 o1-프리뷰 등 순으로 나타났다.
연구진은 리더보드가 지속적으로 업데이트될 것이라고 했다. 더불어 연구진은 "우리는 포괄적인 벤치마킹 방법과 지속적인 연구 및 개발이 AI 시스템을 개선할 것이라고 믿는다"라고 강조했다.
AI포스트(AIPOST) 조형주 기자 aipostkorea@naver.com